Tomoya's Blog
【Python】Data scraping with automation by Selenium
May 20, 2020 • ☕️ 3 min read
Hey, I’m Tomoya again.
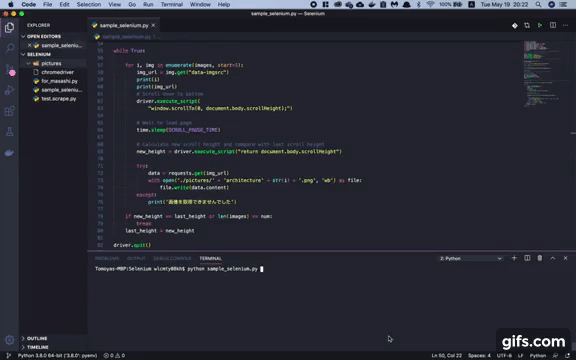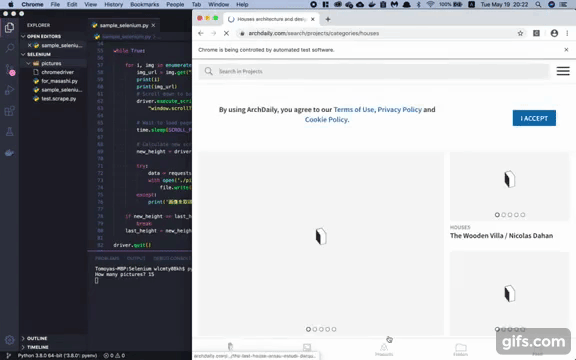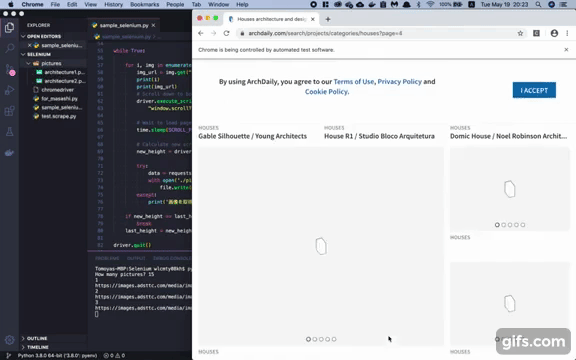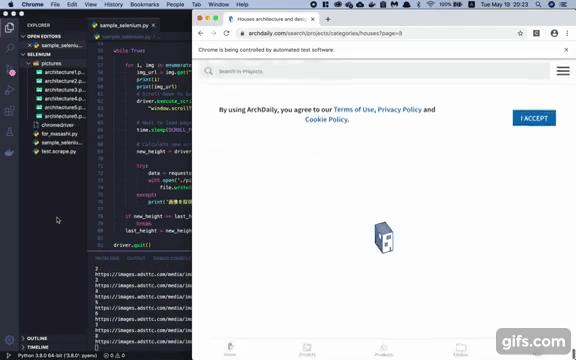
These days I’ve been learning Python a lot so I tried to write a automation program which automatically scrolls down the web page and save the images you want instead of you.
( The program on this post is available only for this particular page since how to scrape a web page depends on what structure it is written on)
Source code
Here’s the source code of this program. Just full of copy & paste though.
# import necessary python libraries
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.alert import Alert
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import requests
import time
# import os # to enable it to execute OS commands such as mkdir
# to enable Selenium to run ChromeDriver in any sort of environment
options = Options()
options.add_argument('--disable-gpu')
options.add_argument('--disable-extensions')
options.add_argument('--proxy-server="direct://"')
options.add_argument('--proxy-bypass-list=*')
options.add_argument('--start-maximized')
# options.add_argument('--headless'); # to use headless mode
how_many = input("How many pictures? ")
num = int(how_many)
DRIVER_PATH = '{インストールしたchromedriverのパスを入れる}'
# i.e.) DRIVER_PATH = '/Users/wlcmty08kh/Desktop/Selenium/chromedriver'
# run Chrome Driver
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
# access the web page
url = 'https://www.archdaily.com/search/projects/categories/houses'
driver.get(url)
# get the HTML source retouch it with BeautifulSoup
current_url = driver.current_url
html = requests.get(current_url)
bs = BeautifulSoup(html.text, "lxml")
# get img tags
images = bs.find_all("img", limit=num + 1)
images.pop(0) # 最初のロゴ画像だけ保存対象から除外
# how long it waits for next scroll
SCROLL_PAUSE_TIME = 1
# get scrollHeight
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# get URLs from the img tags, and put them into img_url
for i, img in enumerate(images, start=1):
img_url = img.get("data-imgsrc")
print(i)
print(img_url)
# scroll down
driver.execute_script(
"window.scrollTo(0, document.body.scrollHeight);")
# wait for next scroll
time.sleep(SCROLL_PAUSE_TIME)
# get scrollHeight
new_height = driver.execute_script("return document.body.scrollHeight")
# write data from img_url in a new file in pictures directory
try:
data = requests.get(img_url)
with open('./pictures/' + 'architecture' + str(i) + '.png', 'wb') as file:
file.write(data.content)
# error handling
except:
print('画像を取得できませんでした') # it says "failed to get a image" in Japanese
# break on "can't scroll down anymore" or "already got enough images"
if new_height == last_height or i == num:
break
last_height = new_height
# quit Chrome Driver
driver.quit()What you need to know before scraping
Either it’s malicious or not, any web scraping can cause too much access on the targeted web page, which brings large loads on its server. Even though web scraping is useful for those who want to gather big information quickly, you need to be aware of these risks.
Tomoya
References:
スクレイピングとは?活用方法や注意点、確認すべきことを徹底解説!
【完全版】PythonとSeleniumでブラウザを自動操作(クローリング/スクレイピング)するチートシート
Pythonにおけるopen関数のwbの利用方法を現役エンジニアが解説【初心者向け】
サイトから画像を取得して保存 | geek開発日誌
Seleniumを安定稼働させるために行うべき3つの設定(Headlessモードにも対応)
Relative Posts:
RubyとPythonの比較
May 17, 2020
To output what I learn from things, and brush up both English & Japanese writing skills. 日々感じたことや学んだことを日本語と英語でアウトプットするための技術系ブログ