Tomoya's Blog
【Python】Seleniumによる自動化でスクレイピング
May 20, 2020 • ☕️ 2 min read
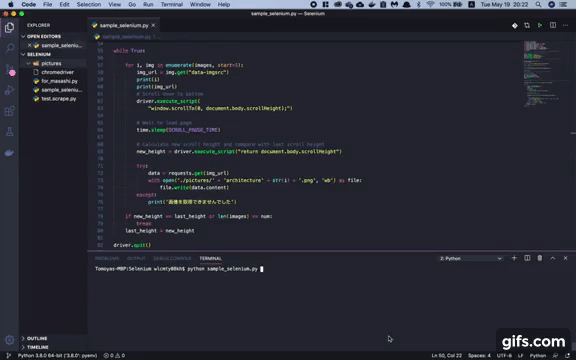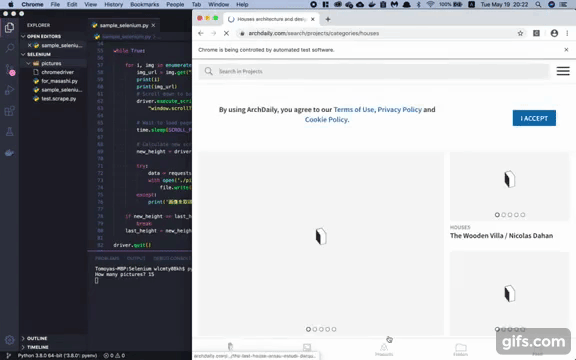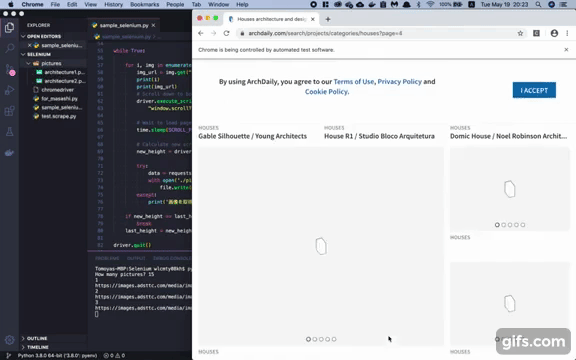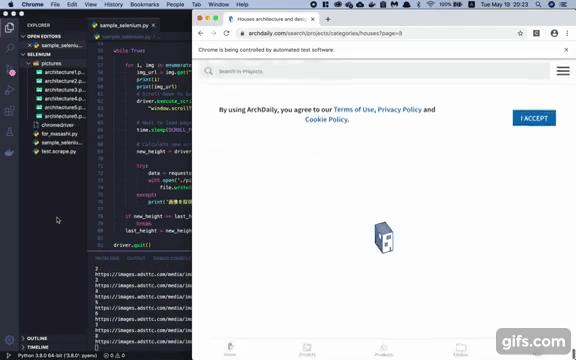
Pythonで何かプログラムを作ってみたいと思ったので、Seleniumやその他ライブラリを使用して、あるサイト内の画像を欲しい数だけ自動で保存してくれるプログラムを作成してみた。 (スクレイピングする対象によって必要なコードも異なるので、今回の対象となるこちらの建築物のまとめサイト以外のサイトに同じプログラムを実行しても成功しないので注意)
ソースコード
Python初学者なのでほとんどがネット上の記事のコピペだが、こちらにソースコードを載せておく。
# 必要なライブラリ等をimportする
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.alert import Alert
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import requests
import time
# import os # プログラム内でmkdirなどのコマンドを実行したい場合は、コメントアウトを外す
# Seleniumをあらゆる環境で起動させるChromeオプション
options = Options()
options.add_argument('--disable-gpu')
options.add_argument('--disable-extensions')
options.add_argument('--proxy-server="direct://"')
options.add_argument('--proxy-bypass-list=*')
options.add_argument('--start-maximized')
# options.add_argument('--headless'); # ※ヘッドレスモードを使用する場合、コメントアウトを外す
# 取得してもらいたい画像の枚数を入力してもらう
how_many = input("How many pictures? ")
num = int(how_many)
DRIVER_PATH = '{インストールしたchromedriverのパスを入れる}'
# 例) DRIVER_PATH = '/Users/wlcmty08kh/Desktop/Selenium/chromedriver'
# 仮装ブラウザでchromeを起動
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
# Webページにアクセスする
url = 'https://www.archdaily.com/search/projects/categories/houses'
driver.get(url)
# そのページのHTMLソースを取得し、BeautifulSoupで要素を取得しやすいよう加工
current_url = driver.current_url
html = requests.get(current_url)
bs = BeautifulSoup(html.text, "lxml")
# 取得したい画像の数だけimgタグを取得
images = bs.find_all("img", limit=num + 1)
images.pop(0) # 最初のロゴ画像だけ保存対象から除外
# 次のスクロールの待ち時間
SCROLL_PAUSE_TIME = 1
# scrollHeightを取得
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# for文でそれぞれのimgタグから画像URLを取得して、img_urlに入れる
for i, img in enumerate(images, start=1):
img_url = img.get("data-imgsrc")
print(i)
print(img_url)
# 下までスクロール
driver.execute_script(
"window.scrollTo(0, document.body.scrollHeight);")
# 次のスクロールの前にページがロードされるのを待つ
time.sleep(SCROLL_PAUSE_TIME)
# この時点でのscrollHeightを取得
new_height = driver.execute_script("return document.body.scrollHeight")
# Picturesというフォルダに任意の名前でファイルを作成し、img_urlから取得できるデータをそのファイルに書き込んで保存
try:
data = requests.get(img_url)
with open('./pictures/' + 'architecture' + str(i) + '.png', 'wb') as file:
file.write(data.content)
# 途中でエラーが発生したら、エラーメッセージをprintする
except:
print('画像を取得できませんでした')
# これ以上スクロールできなくなる or 取得したい数の画像を取得したら処理を終了
if new_height == last_height or i == num:
break
last_height = new_height
# 仮装ブラウザのchromeを終了
driver.quit()スクレイピングする前に知っておくべきこと
スクレイピングは効率よく情報やデータを取得するのに便利だが、その仕組みや対象となるWebページの運営側に迷惑をかけてしまう危険性があることを理解しなければならない。同じWebページへのスクレイピングを短いスパンで大量に行ってしまうと、相手のサーバに大きな負荷を掛けることに繋がる。日本では少ないが、海外ではスクレイピングによるトラブルで裁判沙汰になるケースも少なくない。
あとがき
今回Seleniumというライブラリで仮想のChromeを自動操作してページを表示させたりスクロールさせることができた。載せてはいないがキーワードで検索してページ遷移するのも簡単だったのでいつかまとめて載せようと思う。自動化は楽しいが、調子に乗ってスクレイピングしすぎないよう気をつけよう。
Tomoya
参考にした記事:
スクレイピングとは?活用方法や注意点、確認すべきことを徹底解説!
【完全版】PythonとSeleniumでブラウザを自動操作(クローリング/スクレイピング)するチートシート
Pythonにおけるopen関数のwbの利用方法を現役エンジニアが解説【初心者向け】
サイトから画像を取得して保存 | geek開発日誌
Seleniumを安定稼働させるために行うべき3つの設定(Headlessモードにも対応)
Relative Posts:
【Python】Data scraping with automation by Selenium
May 20, 2020
To output what I learn from things, and brush up both English & Japanese writing skills. 日々感じたことや学んだことを日本語と英語でアウトプットするための技術系ブログ